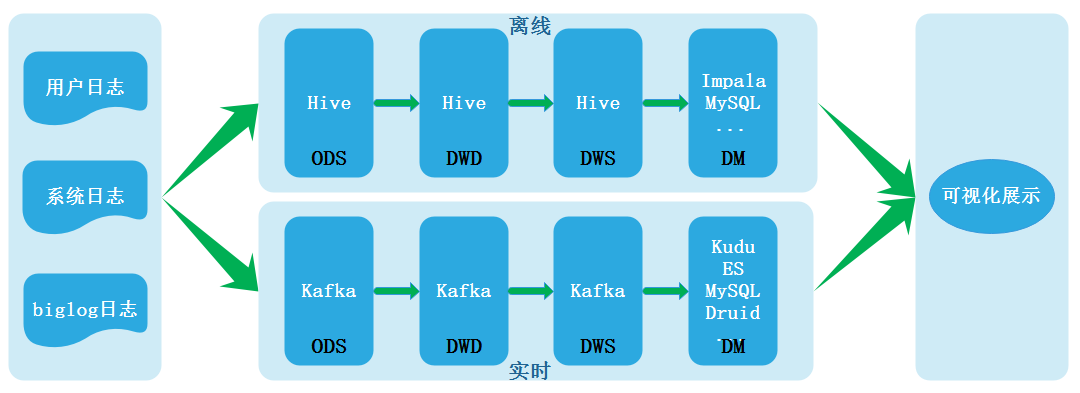
在现代数据仓库架构中,离线数仓和实时数仓是两种常见的数据处理模式,它们在数据处理的时效性、存储支持服务及应用场景上存在显著差异。本文将深入探讨两者的核心区别,并重点分析其存储支持服务的不同。
一、离线数仓与实时数仓的核心区别
- 数据处理时效性:离线数仓主要处理历史数据,通常以天、周或月为周期进行批量处理,数据延迟较高;而实时数仓则处理实时或近实时数据,以秒或分钟为单位,支持低延迟的数据访问和查询。
- 应用场景:离线数仓适用于报表生成、历史趋势分析和批处理任务,如电商的月度销售报告;实时数仓常用于实时监控、风险控制和推荐系统,如金融交易欺诈检测。
- 架构复杂度:离线数仓通常采用批处理框架(如Hadoop MapReduce、Spark),架构相对简单;实时数仓则依赖流处理技术(如Apache Kafka、Flink),需要更复杂的管道来保证数据连续性。
二、存储支持服务的差异
在存储方面,离线数仓和实时数仓的差异主要体现在数据存储格式、存储引擎和扩展性上:
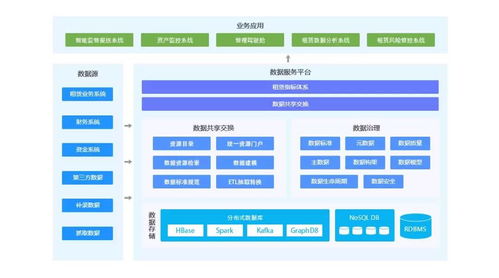
- 离线数仓存储支持:通常基于分布式文件系统(如HDFS)或列式存储(如Apache Parquet、ORC),支持高吞吐量的批量读写。存储服务注重成本效益和容错性,例如使用云存储(如AWS S3)或Hadoop生态工具。数据分区和压缩优化是关键,以提升查询效率。
- 实时数仓存储支持:强调低延迟和高并发,常用内存数据库(如Redis)、时序数据库(如InfluxDB)或分布式KV存储(如HBase)。云原生服务(如Google BigQuery或Amazon Redshift)也提供实时分析能力。存储设计需支持快速数据摄入和实时索引,以确保秒级响应。
三、总结与建议
离线数仓和实时数仓并非互斥,而是互补的。企业在选择时,应根据业务需求权衡:若需深度历史分析,离线数仓更经济;若追求即时洞察,实时数仓更优。存储支持服务的选择直接影响性能,建议结合数据量、延迟要求和成本进行综合评估,例如在混合架构中,使用离线数仓存储历史数据,实时数仓处理热点数据,以实现高效的数据管理。