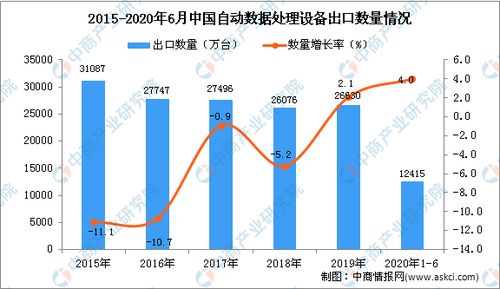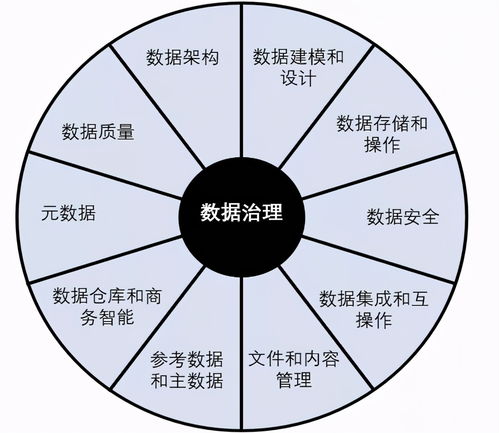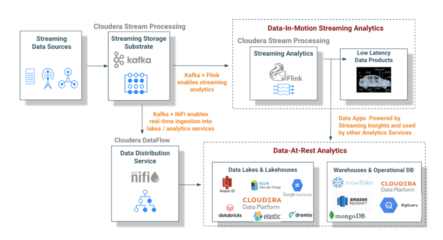
在当今数据驱动的时代,海量、实时、多源的数据流已成为企业运营和决策的核心资产。原始的数据流本身价值有限,只有经过有效的采集、处理、存储和治理,才能转化为可供分析、应用和交易的标准化“数据产品”。在这一转化链条中,存储支持服务扮演着至关重要的基石角色。它不仅关乎数据的“存得住”,更关乎如何“存得好”、“用得快”、“管得稳”,是释放数据价值、赋能业务创新的关键支撑。
一、数据流的挑战与存储服务的基础要求
数据流通常具有高吞吐、低延迟、格式多样(如日志、事件、传感器读数、交易记录等)和持续不断的特点。传统的存储方案(如关系型数据库)往往难以应对这种“流”的特性。因此,专门的存储支持服务需满足以下核心要求:
- 高吞吐与低延迟写入:能够实时、持续地接收并持久化高速涌入的数据流,避免数据丢失或积压。
- 弹性可扩展:存储容量和性能能够随数据量的增长近乎线性地平滑扩展,无需频繁的架构重构。
- 多模态数据支持:能够灵活存储结构化、半结构化(如JSON、XML)和非结构化数据,适应多样化的数据来源。
- 成本效益:在保证性能的前提下,通过分层存储(热、温、冷)、数据压缩、生命周期管理等手段,有效控制存储成本。
二、构建服务于数据产品化的存储架构
要将数据流转化为高价值的数据产品,存储服务不能仅停留在“数据湖”或“数据仓库”的简单概念上,而应是一个分层、协同的体系:
- 实时接入层:作为数据流的“入口”,采用如Apache Kafka、Pulsar等消息队列或流存储系统,负责缓冲和有序分发高速数据流,为后续处理提供稳定源。
- 原始数据存储层(数据湖):使用对象存储(如AWS S3、阿里云OSS)或分布式文件系统(如HDFS),以低成本、高可靠的方式持久化原始的、未经加工的数据流,保留最大的数据保真度和灵活性,为探索性分析和回溯提供基础。
- 加工处理与模型存储层:在此层,数据流被清洗、转换、聚合,形成主题明确、质量可控的数据集(即数据产品的雏形)。此层可能使用高性能的NoSQL数据库(如Cassandra、HBase)、NewSQL数据库或专用的分析型数据库,支持复杂的查询和模型训练。机器学习模型本身作为关键的数据产品,也需要版本化、可追溯的存储服务。
- 服务与集市层:这是数据产品对外交付的“货架”。经过深度加工和封装的数据产品,以API、数据服务、可视化报表等形式提供。此层存储需要极高的查询并发能力和低延迟,常使用OLAP数据库(如ClickHouse、Doris)、图数据库或内存数据库,确保终端用户和业务系统能够高效消费数据价值。
三、存储支持服务的核心能力演进
现代存储支持服务已超越单纯的硬件或软件,演进为一套集成了智能管理、安全合规和运维自动化的综合能力平台:
- 智能数据治理与元数据管理:自动采集、维护数据血缘、质量指标、业务术语表等元数据,使数据流从“黑盒”变为“白盒”,确保数据产品的可发现、可理解、可信赖。
- 统一的安全与访问控制:贯穿数据全生命周期,实施细粒度的权限策略、数据加密(静态/传输中)、脱敏和审计追踪,满足数据安全合规要求,保障数据产品在流通中的安全。
- 自动化运维与可观测性:提供存储资源的自动部署、弹性伸缩、备份恢复、性能监控与告警。通过可观测性工具,实时洞察存储系统的健康状态和数据流动效率。
- 数据生命周期智能管理:根据数据产品的热度、访问模式和价值变化,自动执行数据在不同存储介质(如SSD、HDD、归档存储)间的迁移、降冷或清理策略,实现成本与性能的最优平衡。
四、实践路径与未来展望
企业构建此类存储支持服务,通常遵循“平台化+服务化”的路径:选择或搭建统一的技术平台,整合各类存储引擎;在平台之上构建自助服务门户和标准化接口,让数据开发者和产品经理能够便捷地申请、使用和管理存储资源;形成面向不同业务场景的、即开即用的存储服务目录。
随着云原生、存算分离、湖仓一体等架构的普及,存储支持服务将更加无缝、智能和无感。人工智能将更深地融入数据管理,实现自动化的数据分类、异常检测和性能调优。存储的边界也将进一步模糊,与计算、网络、安全更紧密地融合,共同构成数据产品化过程中坚实、敏捷且经济高效的“数字底座”。
结论:将汹涌的数据流转化为可消费、可增值的数据产品,是一项系统工程。其中,现代化、智能化的存储支持服务是确保这一转化过程高效、可靠、安全进行的基础设施。它不仅是数据的“容器”,更是数据价值炼金术的“熔炉”和“传送带”,直接决定了数据产品的质量、交付速度和最终的业务影响力。投资于强大的存储支持服务,就是投资于企业未来的数据核心竞争力。