随着企业数据量的持续增长,如何高效管理海量数据并挖掘其价值,已成为企业数字化转型过程中的关键挑战。阿里云数据库服务RDS(关系型数据库服务)和POLARDB(云原生数据库)作为企业级数据库解决方案,提供了强大的数据存储与处理能力。而X-Pack Spark作为阿里云上的大数据计算与分析服务,能够与RDS和POLARDB无缝集成,实现数据的高效归档、计算和存储支持。本文将介绍将RDS和POLARDB数据归档到X-Pack Spark的最佳实践,帮助企业构建灵活、可扩展的数据处理架构。
一、数据归档背景与需求
在业务运营中,RDS和POLARDB通常存储着核心交易数据和实时业务信息。随着数据量的积累,数据库的存储压力增大,查询性能可能下降,同时存储成本也会上升。将历史数据或冷数据归档到X-Pack Spark,可以有效减轻数据库负载,降低成本,并利用Spark的强大计算能力进行离线分析、机器学习和数据挖掘。常见应用场景包括:历史交易数据归档、日志数据分析、用户行为分析等。
二、归档架构设计
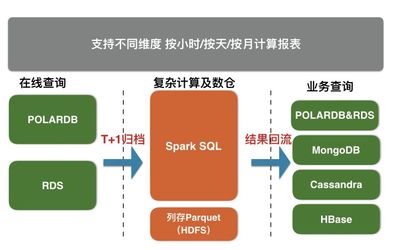
为实现高效的数据归档,建议采用以下架构设计:
- 数据源层:RDS和POLARDB作为数据源,存储实时或热数据。通过数据库的内置工具(如RDS的备份功能或POLARDB的导出工具)将数据导出为兼容格式(如CSV、Parquet或ORC)。
- 传输层:使用阿里云Data Transmission Service(DTS)或自定义脚本,将导出的数据传输到对象存储服务OSS中。OSS作为中间存储,确保数据的安全性和可访问性。
- 计算存储层:X-Pack Spark从OSS中读取数据,进行ETL(提取、转换、加载)处理、归档存储以及计算分析。Spark支持多种数据格式,并可集成HDFS或OSS作为持久化存储,实现数据的长期保留和快速查询。
- 应用层:通过Spark的API或SQL接口,业务应用可以直接访问归档数据,进行报表生成、趋势分析或机器学习任务。
三、实施步骤
- 数据准备:在RDS或POLARDB中识别需要归档的数据,例如通过时间戳筛选历史记录。确保数据导出前进行备份,避免影响线上业务。
- 配置数据传输:使用DTS设置数据同步任务,将数据从数据库导出到OSS。DTS支持全量和增量同步,适用于不同归档频率的需求。如果需要自定义逻辑,可以编写Spark作业直接连接数据库读取数据。
- Spark作业开发:在X-Pack Spark中创建作业,定义数据读取、转换和存储逻辑。例如,使用Spark SQL将数据从OSS加载到DataFrame,进行清洗和聚合后,保存到HDFS或OSS的指定目录。Spark的分布式计算能力可以高效处理TB级数据。
- 监控与优化:通过阿里云监控服务跟踪数据归档任务的性能,包括传输速率、Spark作业执行时间和资源使用情况。根据需求调整Spark集群配置,如增加Executor数量或优化内存分配,以提升效率。
- 安全与权限管理:确保数据传输和存储过程中加密(如SSL/TLS),并设置访问控制策略,防止数据泄露。使用RAM(资源访问管理)角色授权Spark访问OSS和数据库。
四、优势与收益
通过将RDS和POLARDB数据归档到X-Pack Spark,企业可以获得以下收益:
- 成本优化:减少数据库存储开销,利用Spark的弹性计算资源按需付费。
- 性能提升:释放数据库资源,提高实时查询性能,同时Spark支持并行处理,加速数据分析。
- 灵活性增强:支持多种数据格式和计算场景,便于集成AI/ML工具,如MaxCompute或PAI。
- 可扩展性:Spark集群可水平扩展,应对数据量增长,确保长期数据管理能力。
五、总结与建议
数据归档是现代化数据架构的重要组成部分。结合RDS、POLARDB和X-Pack Spark,企业可以构建一个高效、经济的数据生命周期管理方案。建议在实践中,根据业务需求定期评估归档策略,例如设置自动化归档任务,并利用Spark的监控工具进行持续优化。通过这一最佳实践,企业不仅能降低运营成本,还能挖掘数据深层价值,驱动业务创新。