在当今数字化时代,面对用户量激增和数据爆炸式增长,构建能够支撑千万级用户规模的高性能、高并发网络架构成为企业技术团队面临的重要挑战。本文将分享我们在千万级规模网络架构设计和数据处理方面的实战经验。
一、网络架构设计核心原则
1. 横向扩展能力
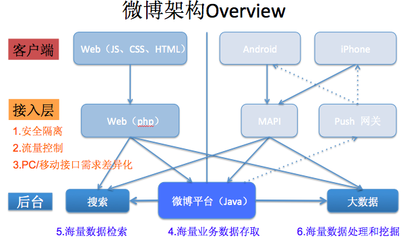
采用微服务架构,将系统拆分为多个独立的服务单元,每个服务都可以独立部署和扩展。通过负载均衡器实现流量分发,确保系统能够根据业务需求弹性伸缩。
2. 分层架构设计
• 接入层:使用LVS/Nginx进行四层/七层负载均衡
• 应用层:采用无状态设计,便于水平扩展
• 缓存层:Redis集群提供高速数据访问
• 数据层:MySQL分库分表,结合读写分离
二、高并发处理策略
1. 异步化处理
对于耗时操作采用消息队列(Kafka/RabbitMQ)进行异步处理,避免阻塞主业务流程。通过削峰填谷,保证系统在高并发场景下的稳定性。
2. 缓存策略优化
• 多级缓存架构:本地缓存+分布式缓存
• 热点数据预加载机制
• 缓存穿透、雪崩防护策略
3. 连接池管理
优化数据库连接池和HTTP连接池配置,减少连接建立和释放的开销,提高资源利用率。
三、数据处理架构设计
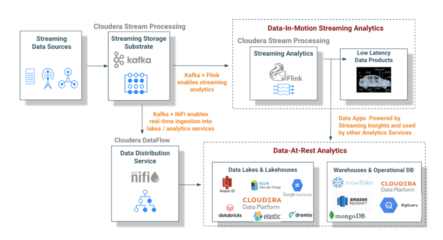
1. 数据采集层
• 日志采集:ELK栈实现实时日志收集和分析
• 指标监控:Prometheus+Grafana构建监控体系
• 数据同步:Canal/Otter实现MySQL增量数据同步
2. 数据存储层
• 在线业务数据:MySQL集群+分库分表
• 非结构化数据:MongoDB集群
• 时序数据:InfluxDB/OpenTSDB
• 搜索数据:Elasticsearch集群
3. 数据处理层
• 实时计算:Flink/Kafka Streams处理实时数据流
• 批量处理:Spark进行大规模数据批处理
• 数据质量:建立数据质量监控和治理体系
四、性能优化实践
1. 网络优化
• CDN加速静态资源访问
• 长连接替代短连接减少TCP握手开销
• 协议优化:HTTP/2多路复用,QUIC协议应用
2. 数据库优化
• 索引优化:覆盖索引、联合索引合理设计
• SQL优化:避免全表扫描,减少JOIN操作
• 分库分表策略:按业务维度拆分,支持线性扩展
3. 代码层面优化
• 对象复用和资源回收
• 算法复杂度优化
• 并发编程最佳实践
五、监控与运维
1. 全链路监控
• 应用性能监控(APM)
• 基础设施监控
• 业务指标监控
2. 自动化运维
• 持续集成/持续部署(CI/CD)
• 自动化扩容缩容
• 故障自愈机制
六、经验总结
- 架构设计的可扩展性比单机性能更重要
- 监控和日志是系统稳定运行的基石
- 数据一致性、可用性、分区容错性需要权衡
- 团队技术能力和运维经验是关键成功因素
在千万级规模的高并发场景下,没有一劳永逸的解决方案。需要根据业务特点不断调整优化,建立完善的监控体系和应急预案,才能在面对流量洪峰时保持系统的稳定可靠。